Inpainting in Stable Diffusion refers to a technique used for modifying or repairing specific parts of an image using artificial intelligence. This process involves generating new content to fill in missing, damaged, or undesired areas of an image while maintaining a coherent and visually appealing result.
Using an image as input for inpainting techniques can yield impressive results and provide greater control over the final composition. If you have a high-quality image with a minor defect, inpainting enables you to create a mask and seamlessly alter that specific area.
Additionally, employing a simple drawing or image as input can lead to remarkable outcomes quickly. You can create variations of the entire image while preserving the original composition, allowing you to explore the influence of both the input image and the accompanying prompt.
Inpainting in Stable Diffusion is a technique used to selectively modify or replace parts of an existing image, such as removing unwanted objects, changing backgrounds, or adding new elements.

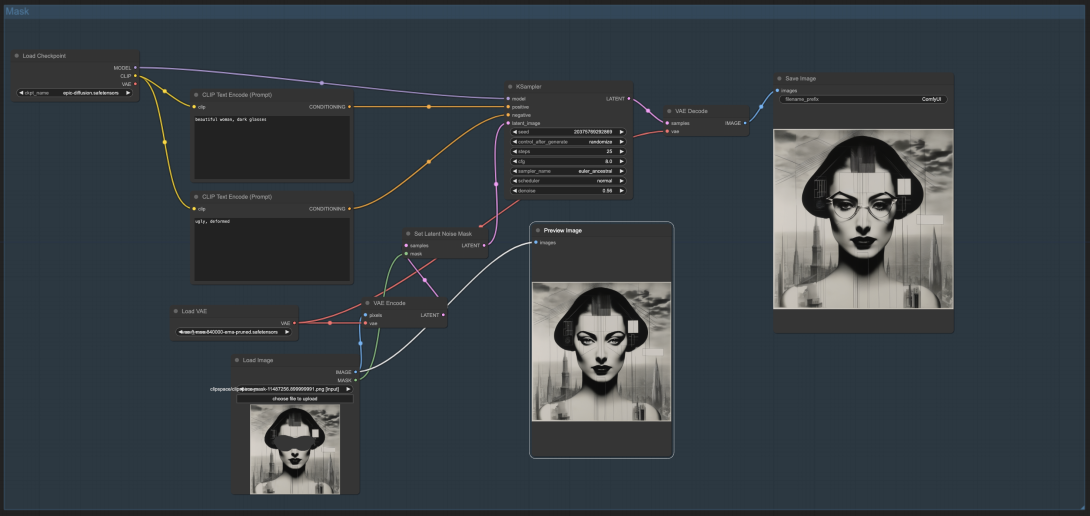
Basic Inpainting Workflow
A typical inpainting workflow consists of the following steps:
- Image Upload: Load the image that needs inpainting into the interface.
- Mask Creation: Define the area to be inpainted by creating a mask over the undesired or missing parts.
- Model Selection: Choose an inpainting model that will be used to generate the new content.
- Inpainting Execution: Run the inpainting process, where the model generates new content for the masked area.
- Review and Adjust: Examine the output and make any necessary adjustments, such as refining the mask or tweaking settings, to achieve the desired result.
Process: Users typically create a mask to define the area they want to modify. The AI then generates new content for that masked area, taking into account the surrounding context.

Prompt guidance: Users can provide text prompts to guide the AI in generating the desired content for the inpainted area.
Understanding Inpainting Models
An inpainting model is a pre-trained neural network specifically designed for the task of inpainting. These models are trained on extensive datasets of images, enabling them to generate plausible content for missing or masked areas.
In the context of Stable Diffusion, the inpainting model utilizes diffusion processes to iteratively refine the generated content, ensuring it integrates seamlessly with the surrounding pixels. Stable Diffusion Inpainting is a latent text-to-image diffusion model capable of generating photo-realistic images given a prompt with the extra capability of inpainting by using a mask.
The first SD inpainting model had 595k steps of regular training and 440k steps of inpainting training.[1] The stable-diffusion-2-inpainting model is resumed from stable-diffusion-2-base and trained for another 200k steps.[2] The SD-XL Inpainting 0.1 is trained for "40k steps at resolution 1024x1024 and 5% dropping of the text-conditioning to improve classifier-free classifier-free guidance sampling."[3]

ControlNet Inpainting
ControlNet is an advanced framework that enhances the capabilities of diffusion models by adding more control mechanisms. In the context of inpainting, ControlNet allows users to have finer control over the inpainting process, enabling more precise and context-aware modifications. This might involve controlling the shape, texture, or specific features of the inpainted area.
Conclusion
Inpainting using Stable Diffusion represents a significant advancement in image processing, allowing for sophisticated and high-quality edits that were previously challenging to achieve with traditional methods. This technique provides users with powerful tools to enhance and modify their visuals by understanding and generating content that blends seamlessly with existing parts of the image. Inpainting relies on masks, which can be created using image segmentation, potentially transforming our approach to image editing and enhancement. These simple inpainting experiments are just the beginning of what's possible with this technology.
Workflow examples:
ComfyUI Fundamentals - Masking - Inpainting
Further reference:
Huggingface Everything Inpaint
Let's understand Stable Diffusion Inpainting
Lesson 4: Img2Img Painting in ComfyUI - Comfy Academy
Lesson 5: Magical Img2Img Render + WD14 in ComfyUI - Comfy Academy
Lesson 6: Model Switch and Masking in ComfyUI - Comfy Academy
Inpainting With ComfyUI — Basic Workflow & With ControlNet
